Το Skipfish είναι ένα εργαλείο εύρεσης ευπαθειών σε περιβάλλον web εφαρμογών. O τρόπος με τον οποίο λειτουργεί είναι να δημιουργεί ένα διαδραστικό sitemap για το website που υπόκειται ανάλυση μέσω της χρήσης crawls και probes λεξικού. Στο map που τελικά προκύπτει συμπεριλαμβάνονται και τα αποτελέσματα από επιπλέον ελέγχους ασφαλείας που πραγματοποιεί. Το τελικό report που παράγει το Skipfish μπορεί να χρησιμοποιηθεί σαν βάση για επαγγελματικές αξιολογήσεις ασφαλείας σε web εφαρμογές.
Τα κύρια χαρακτηριστικά του συνοψίζονται παρακάτω:
- Μεγάλη ταχύτητα: γραμμένο σε γλώσσα C, εξαιρετικός χειρισμός HTTP, μπορεί να πραγματοποιήσει πολύ εύκολα 2000 requests ανά δευτερόλεπτο απέναντι σε στόχους/μηχανήματα προς ανάλυση.
- Ευκολία στη χρήση
- Πρωτοποριακή λογική ασφαλείας: υψηλή ποιότητα, λίγα false positives, έλεγχος ασφάλειας, ικανός να εντοπίζει ακόμα και τα πιο ανεπαίσθητα θέματα ασφαλείας.

Πως να το εγκαταστήσετε
Η εγκατάσταση του Skipfish υποστηρίζεται μόνο σε περιβάλλον Linux. Θα το βρείτε προ-εγκατεστημένο στο πολύ γνωστό distro, Kali Linux.
Ubuntu & Debian

{kind=link}
Για να εγκαταστήσετε το Skipfish σε περιβάλλον ubuntu και debian ανοίξτε ένα terminal και πληκτρολογήστε τις παρακάτω εντολές:
| sudo apt-get update -y sudo apt-get install -y skipfish |
CentOs
Για να εγκαταστήσετε το Skipfish σε περιβάλλον CentOs ανοίξτε ένα terminal και πληκτρολογήστε τη παρακάτω εντολή:
| yum install skipfish |
Πως να το χρησιμοποιήσετε
Για να δούμε τις διαφορετικές παραμέτρους που μπορούμε να χρησιμοποιήσουμε σε αυτό το εργαλείο θα ανοίξουμε ένα terminal και θα τρέξουμε τη παρακάτω εντολή:
| skipfish –help |
Το αποτέλεσμα φαίνεται παρακάτω.
root@kali-elena:~# skipfish --help skipfish web application scanner - version 2.10b Usage: skipfish [ options ... ] -W wordlist -o output_dir start_url [ start_url2 ... ] Authentication and access options: -A user:pass - use specified HTTP authentication credentials -F host=IP - pretend that 'host' resolves to 'IP' -C name=val - append a custom cookie to all requests -H name=val - append a custom HTTP header to all requests -b (i|f|p) - use headers consistent with MSIE / Firefox / iPhone -N - do not accept any new cookies --auth-form url - form authentication URL --auth-user user - form authentication user --auth-pass pass - form authentication password --auth-verify-url - URL for in-session detection Crawl scope options: -d max_depth - maximum crawl tree depth (16) -c max_child - maximum children to index per node (512) -x max_desc - maximum descendants to index per branch (8192) -r r_limit - max total number of requests to send (100000000) -p crawl% - node and link crawl probability (100%) -q hex - repeat probabilistic scan with given seed -I string - only follow URLs matching 'string' -X string - exclude URLs matching 'string' -K string - do not fuzz parameters named 'string' -D domain - crawl cross-site links to another domain -B domain - trust, but do not crawl, another domain -Z - do not descend into 5xx locations -O - do not submit any forms -P - do not parse HTML, etc, to find new links Reporting options: -o dir - write output to specified directory (required) -M - log warnings about mixed content / non-SSL passwords -E - log all HTTP/1.0 / HTTP/1.1 caching intent mismatches -U - log all external URLs and e-mails seen -Q - completely suppress duplicate nodes in reports -u - be quiet, disable realtime progress stats -v - enable runtime logging (to stderr) Dictionary management options: -W wordlist - use a specified read-write wordlist (required) -S wordlist - load a supplemental read-only wordlist -L - do not auto-learn new keywords for the site -Y - do not fuzz extensions in directory brute-force -R age - purge words hit more than 'age' scans ago -T name=val - add new form auto-fill rule -G max_guess - maximum number of keyword guesses to keep (256) -z sigfile - load signatures from this file Performance settings: -g max_conn - max simultaneous TCP connections, global (40) -m host_conn - max simultaneous connections, per target IP (10) -f max_fail - max number of consecutive HTTP errors (100) -t req_tmout - total request response timeout (20 s) -w rw_tmout - individual network I/O timeout (10 s) -i idle_tmout - timeout on idle HTTP connections (10 s) -s s_limit - response size limit (400000 B) -e - do not keep binary responses for reporting Other settings: -l max_req - max requests per second (0.000000) -k duration - stop scanning after the given duration h:m:s --config file - load the specified configuration file Send comments and complaints to <heinenn@google.com>. |
Ας ξεκινήσουμε το scan στο site που έχουμε φτιάξει μόνο για αυτό το λόγο (IP: 192.168.142.29). Για να το κάνουμε αυτό και να “γράψουμε” το αποτέλεσμα σε ένα directory θα πρέπει να χρησιμοποιήσουμε τη παράμετρο -o και να εκτελέσουμε την παρακάτω εντολή:
| skipfish -o skip http://192.168.142.129 |
Όσο το scan τρέχει, αποθηκεύει τα αποτελέσματα στο φάκελο skip και εμείς στην οθόνη μας βλέπουμε κάτι σαν αυτό που φαίνεται παρακάτω:
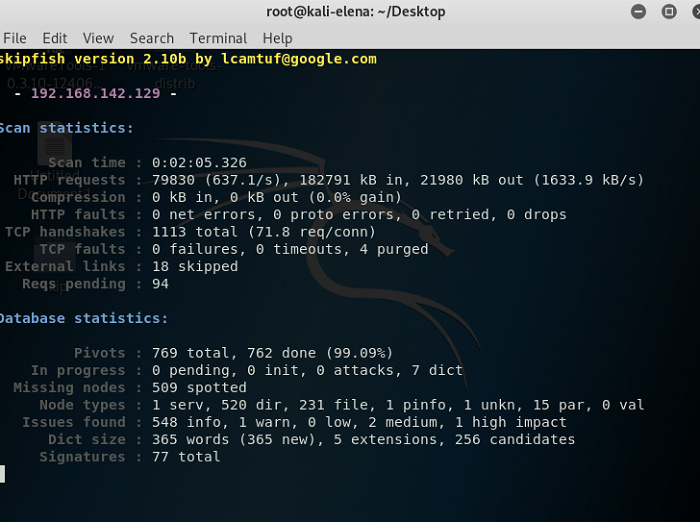
Όταν το scan ολοκληρωθεί θα δούμε στην οθόνη κάτι που θα μοιάζει με το παρακάτω:
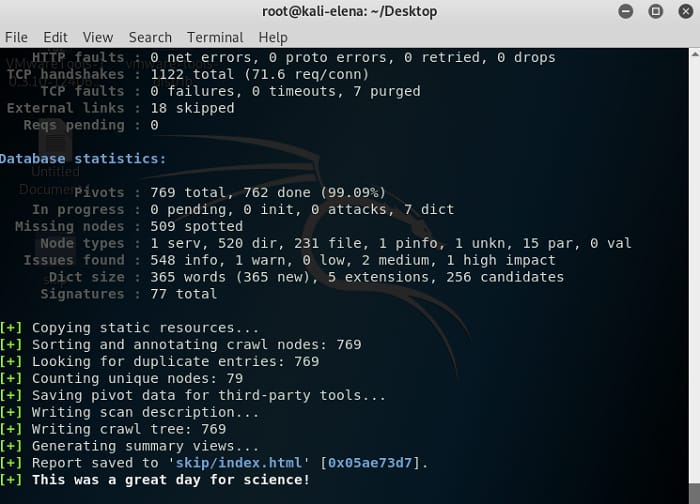
Ας πάμε να δούμε τα αποτελέσματα του crawl στο αρχείο index.html στο φάκελο skip.
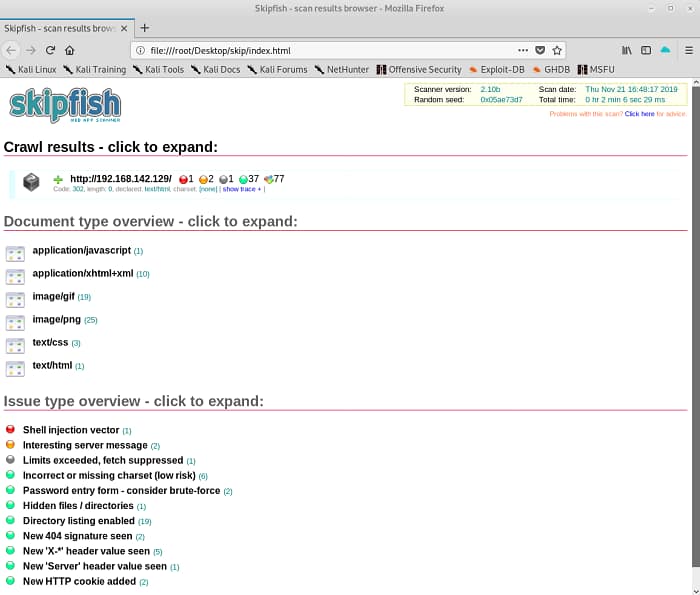
Βλέπουμε λοιπόν ένα πολύ ωραίο report που προέκυψε μετά από αξιολόγηση της εφαρμογής και μας δείχνει όλες τις ευπάθειες που αναγνώρισε το skipfish κατά τη διάρκεια του scan. Μπορούμε να κλικάρουμε κάθε finding για να δούμε περισσότερες πληροφορίες, όπως το που ακριβώς βρέθηκε.
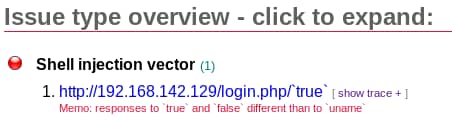
Επιλέγοντας το “show trace” θα δούμε το evidence που σχετίζεται με την συγκεκριμένη ευπάθεια. Για το “Shell injection vector” που επιλέξαμε πιο πάνω, το trace που σχετίζεται με αυτό φαίνεται παρακάτω:
=== REQUEST === GET /login.php/`true` HTTP/1.1 Host: 192.168.142.129 Accept-Encoding: gzip Connection: keep-alive User-Agent: Mozilla/5.0 SF/2.10b Range: bytes=0-399999 Referer: http://192.168.142.129/ Cookie: PHPSESSID=94lthp20g1r5iu32anumr9e0o1; security=high === RESPONSE === HTTP/1.1 200 Partial Content Date: Thu, 21 Nov 2019 21:47:19 GMT Server: Apache/2.2.14 (Unix) DAV/2 mod_ssl/2.2.14 OpenSSL/0.9.8l PHP/5.3.1 mod_apreq2-20090110/2.7.1 mod_perl/2.0.4 Perl/v5.10.1 X-Powered-By: PHP/5.3.1 Expires: Tue, 23 Jun 2009 12:00:00 GMT Cache-Control: no-cache, must-revalidate Pragma: no-cache Content-Range: bytes 0-1223/1224 Content-Length: 1224 Keep-Alive: timeout=5, max=95 Connection: Keep-Alive Content-Type: text/html;charset=utf-8 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>Damn Vulnerable Web App (DVWA) - Login</title> <link rel="stylesheet" type="text/css" href="dvwa/css/login.css" /> </head> <body> <div align="center"> <br /> <p><img src="dvwa/images/login_logo.png" /></p> <br /> <form action="login.php" method="post"> <fieldset> <label for="user">Username</label> <input type="text" class="loginInput" size="20" name="username"><br /> <label for="pass">Password</label> <input type="password" class="loginInput" AUTOCOMPLETE="off" size="20" name="password"><br /> <p class="submit"><input type="submit" value="Login" name="Login"></p> </fieldset> </form> <br /> <br /> <br /> <br /> <br /> <br /> <br /> <br /> <br /> <!-- <img src="dvwa/images/RandomStorm.png" /> --> <p>Damn Vulnerable Web Application (DVWA) is a RandomStorm OpenSource project</p> </div> <!-- end align div --> </body> </html> === END OF DATA === |
Περιμένουμε τα σχόλιά σας για το Skipfish …